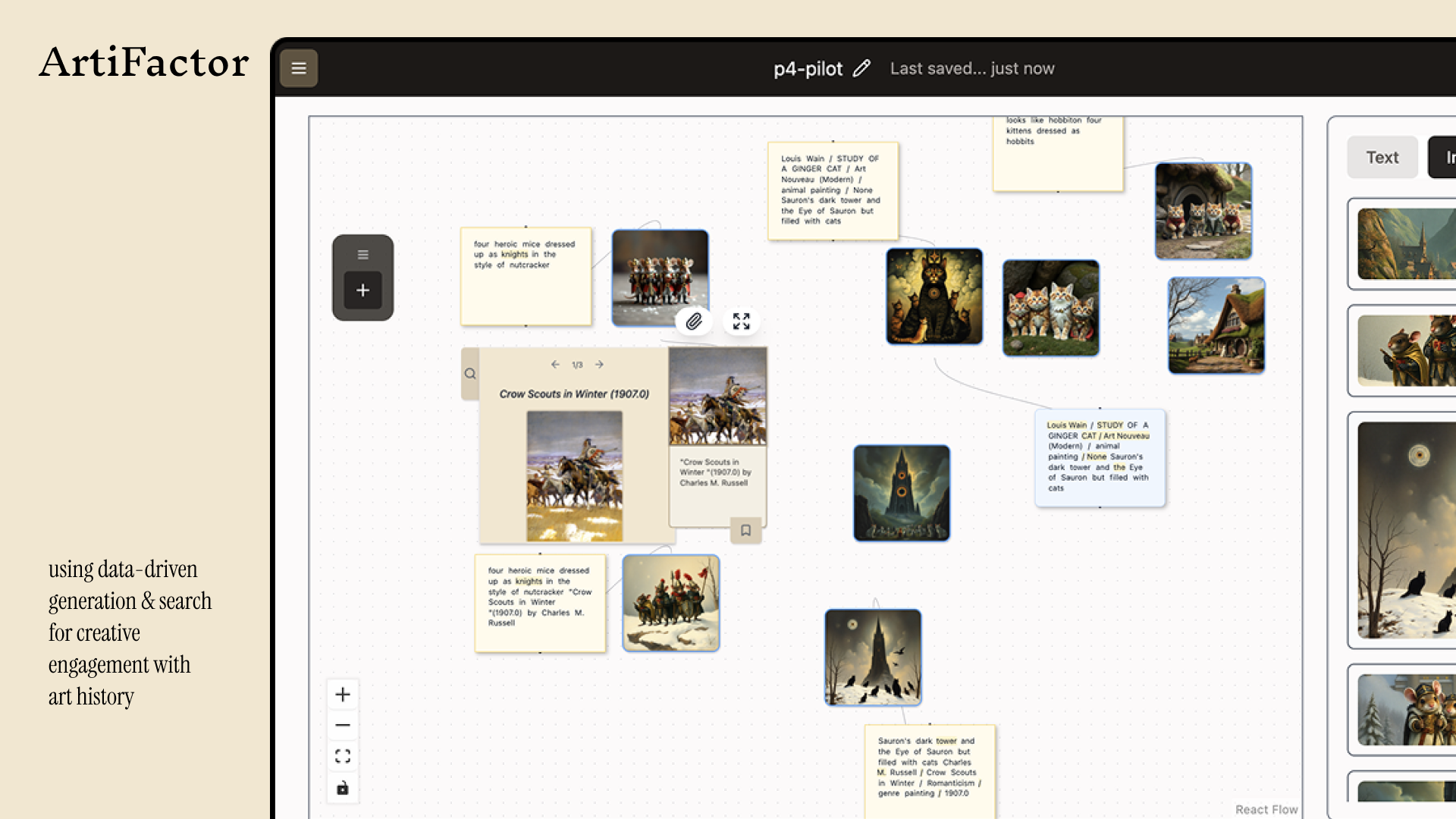
ArtiFactor is a creativity support tool that treats multimodal AI as a material for thinking with art history, rather than just a black-box image generator. On an infinite canvas, users work with “artifacts” – text prompts, generated images, retrieved artworks, and historical background – and use them as reusable materials in their creative process. The system records derivations between artifacts, so users can see how ideas evolve and how historical references shape their final concepts.
Text-to-image and vision-language models have changed how people create and discover media, but most interfaces still center around opaque prompting or chatting. This makes AI feel powerful yet shallow: users get impressive images, but little sense of where styles come from, how they relate to art history, or how to communicate their process with collaborators.
ArtiFactor explores a different approach: using multimodal AI to support material interactions with historical media, turning artworks and texts into traceable, recombinable materials for creative work.
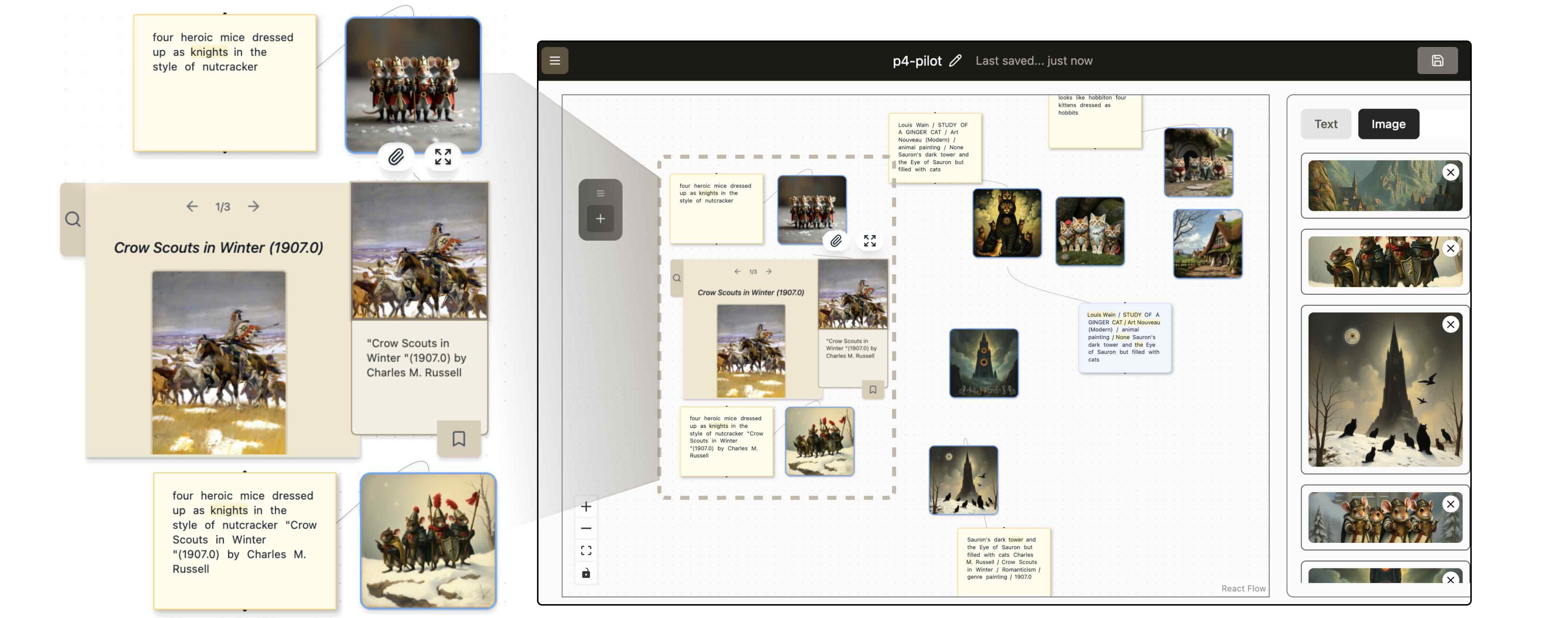
ArtiFactor presents an infinite canvas populated with multimodal artifacts:
Text artifacts – users’ ideas, prompts, and AI-generated descriptions
Image artifacts – AI-generated concepts and historical artworks
Lookup tabs – retrieved related works and art-historical context for each artifact
Users can:
Create & gather materials by generating images or text from any artifact and looking up related artworks in the art history database.
Explore context through the Lookup tab, which surfaces visually similar artworks and background articles that can be dragged onto the canvas as new materials.
Combine materials using a “merge” action that fuses multiple text or image artifacts to generate new concepts and visuals, emphasizing crafting with materials over writing new prompts from scratch.
Trace lineage & share through visible edges between artifacts that show how each item was derived from earlier ones, making a creative process legible to collaborators.
This interaction model shifts the focus from “prompt hacking” to building a visible, shareable history of ideas grounded in specific works and contexts.
Frontend: Infinite-canvas interface built with TypeScript, React, Vite, and Tailwind CSS, including custom node types for text, image, and synthesizer artifacts.
Backend & knowledge server: Node-based backend and a separate knowledge server that connect to a curated art history database, supporting lookup of visually and semantically related works.
Multimodal AI pipeline:
uses text-to-image models to generate concept art from user prompts
uses vision-language models to describe images and populate text artifacts
extracts feature embeddings from images to retrieve visually similar historical artworks
Provenance tracking: each generation, lookup, and merge creates a new artifact and an edge to its parent, enabling provenance and process visualization on the canvas.
In one scenario from our pilot study, a writer–illustrator duo use ArtiFactor to design a graphic novel world about heroic mouse soldiers. The writer starts with a simple idea prompt; ArtiFactor generates concept images, retrieves related artworks like Charles M. Russell’s Crow Scouts in Winter (1907), and surfaces background about the American Old West. By dragging, merging, and reusing these artifacts, the pair gradually develop a consistent, distinctive visual language for their story – and can easily share the full exploration history on the canvas.
Early feedback suggests that this workflow helps people move beyond generic “AI style” images and engage more deeply with historical references and visual storytelling.
Demonstration of ArtiFactor: AI as a Creative Medium for Material Interactions with Art History
Shm Almeda, Bob Tianqi Wei, Ethan Tam, Sophia Liu, Bjoern Hartmann
IN PROGRESS
https://github.com/s-almeda/ArtiFactor
Demo: ArtiFactor
